一、python 常用快捷键: ctrl + / 添加注释/取消注释
ctrl + D 复制粘贴
ctrl + Z 撤销
ctrl + Y 还原/删除
shift + enter 无视光标位置直接换行
ctrl + shift + 上下方向键 将代码上下移动一行
ctrl + alt +L 格式化代码
ctrl + shift +I 查看官方的帮助文档
ctrl + shift + f 查找
ctrl + alt + enter 向上换行
shift + tab 去掉缩进
符号 \n 换行符
\t 制表符
\‘ 字符串内的引号
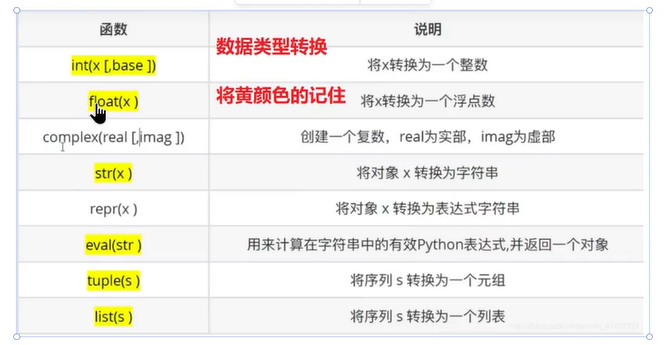
1、变量的类型 识别变量类型
明确指定变量类型
2、输入 输入的内容默认为str
字符串转换:
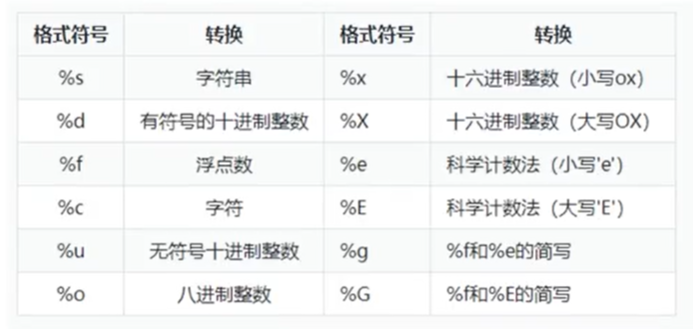
3、输出格式化
1 2 3 4 name = 'QVQ' print ('My name is %s' % name)age = 8888 print ('My name is %s,I`m %d years old' % (name,age))
精确输出
1 2 3 4 5 num = 100 num_1 = 12.345 print ('num =%4d' % num) print ('num =%d' % num) print ('num =%.1f' %num_1)
*输出字符串
1 2 3 print (f'text' )print (f'my name is{name} ' )print ('%s' % name)
(2)运算 4、条件 1 2 3 4 5 6 if 条件1 : 条件1 成立运行的代码 elif 条件2 : 运行的代码 else : 运行的代码
5、循环 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 while 条件: 成立时重复执行的代码 while True : 代码 for 临时变量 in 序列: 重复执行代码 ''' example for i in range (start,end,间隔): #range 包头不包尾 '''
6、序列 (1)切片 1 2 3 4 5 6 7 exa = 'abcdef' print (s[2 :5 :1 ]) print (s[:4 ]) print (s[5 :]) print (s[::-1 ])
(2) 反向序列从-1开始
1 2 3 0 1 2 3 4 5 p y t h o n -6 -5 -4 -3 -2 -1
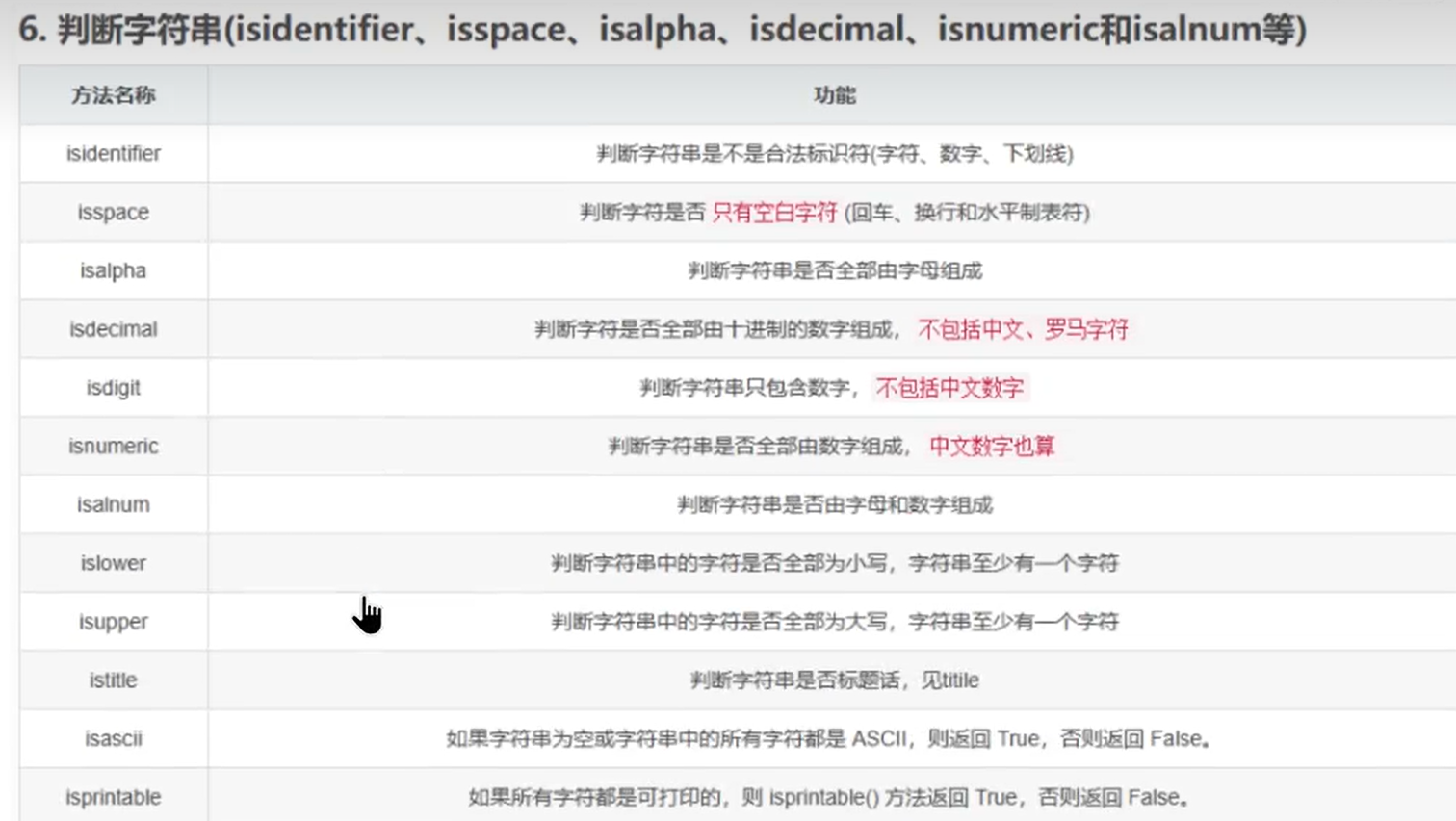
7、字符串 (1)函数字符串查询 find 从左向右查找 rfind 从右向左查找
index 类似于find 若没有会报异常
rindex 类似于 rfind
1 2 3 4 exa = 'abcdef' exa.find('abc' ) 变量名.find('查找的字符串' )
(2)转换大小写 1 2 3 4 5 6 7 str1 = 'xxxx' str2 = str1.upper() str3 = str1.lower() swapcase capitalize title
(3)字符串对齐与分割字符串 1 2 3 4 5 6 7 8 9 10 11 12 center(width,fillchar) ljust rjust ''' 分割字符串 ''' split partition exa = 'I am a student' exa.split(' ' )
(4)字符串替换和判断、去掉多余字符串 1 exa.replace('student' , 'worker' )
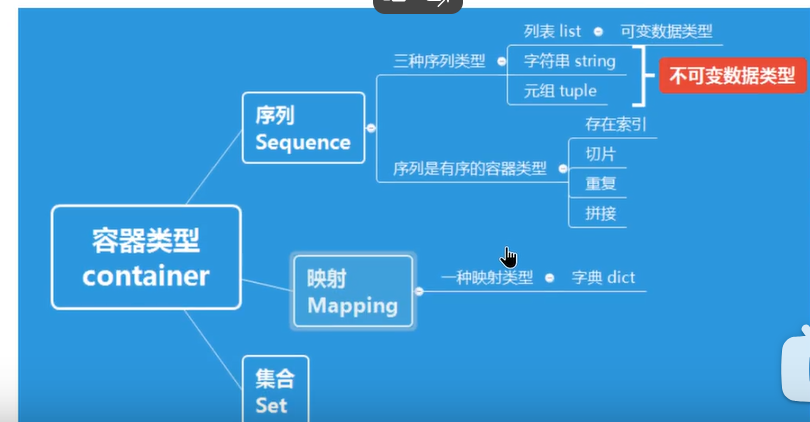
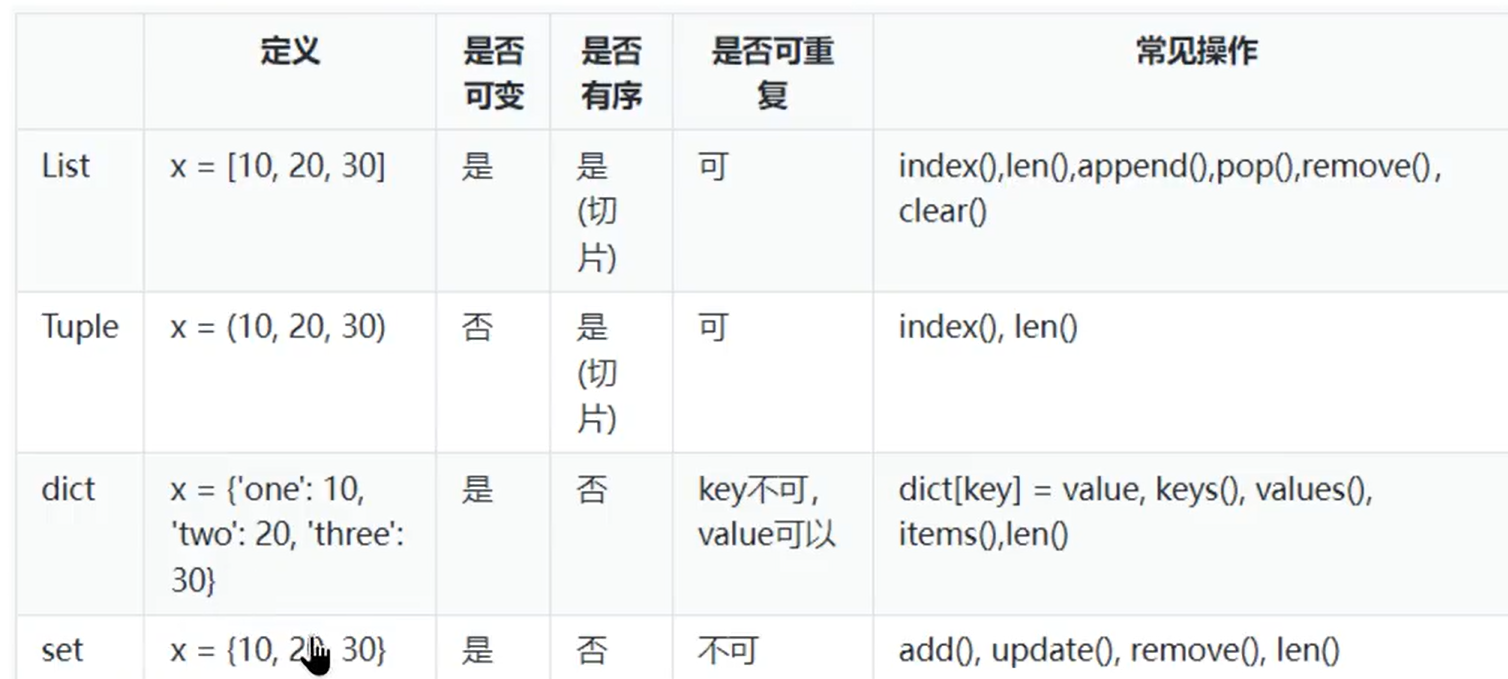
8、List (1) 一次性储存多个数据可为不同类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 list = []list = ['ab' , 123 , '12' ,[1 ,2 ] .....]list [1 ] = 'abc' list .index(123 )list .count(123 )len (list )list .append('hello' )list .extend('world' ) list .insert(0 ,100 ) list .pop() print (list .pop(2 )) list .remove(12 ) del [2 ]
(2)排序 1 2 3 4 5 6 7 8 list [::-1 ]list .reverse()exa = [4 , 9 , 98 . 32 , 2 ] exa.sort exa.sort(reverse = True )
(3)循环遍历 1 2 for i in list : print (i)
9、元组 特点,不可修改
1 2 3 4 5 exa = () exa = ('abc' ,) exa = ('abc' ,12 ,3.14 ,[1 ,2 ]) exa = 'abc' ,12 ,13
操作 1、下标和切片:查找,截取操作
2、index
3、count
4、len(返回元组长度)
5、for
10、序列通用操作(元组,字符串,列表) (1)数学运算符 1 2 3 4 5 + += * *= < <= > >= == !=
(2)成员判断 1 2 3 exa = ('abc' ,12 ,3.14 ,[1 ,2 ]) print (12 in exa) print (12 not in exa)
(3)内置函数 1 2 3 4 5 6 7 t1 = [100 ,200 ,300 ] max (t1) min (t1) sum (t1) max ('hello' )
11、内置容器
(1)字典 字典中的键必须是独一无二的,用’:’隔开
注意:一般冒号前面的为键 k(key),后面的为值 v(value)合起来称为项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 dict1 = {'name' :'QVQ' ,'age' : 888 } dict1 = {} dict2 = dict ([('name' : 'QVQ' ) , ('age' : 888 )]) dict3 = dict (name = 'QVQ' , age = 888 ) dict1['address' ] = 'shanghai' print (dict1) dict1['age' ] = 34 clear dict1.clear dict1.pop('age' ) del dict1['age' ]
函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 dict .fromkeys(['name' ,'age' ])new_dict['name' ] = 'Ling' print (new_dict) print (dict1)print (dict1['address' ]) = print (dict1.get('address' ))for k,v in dict1.items(): print (f'key = {k} ,value = {v} ' ) for k in dict .keys(): print (k) for v in dict .values(): print (v)
12、Set集合 特点:不能重复,不可变类型=没有键的字典,无序无下标,不能放可变类型list
集合创建使用{}或set()
1 2 3 4 5 6 7 8 9 set1 = set () set1 = {'abcdefg' ,100 ,78 ,3.14 } set1.add(99 ) set1.add('hello' ) set1.remove('hello' )
总结
可变:list, dict ,set
不可变: 基本类型(str,int ,float) , tuple
1 2 3 4 5 6 7 s1 = 'helloworld' print (id (s1))s1 = 'abcd' print (id (s1))
函数 1、定义函数 1 2 3 4 5 6 7 8 9 10 11 12 13 def my_abs (参数 ): ''' 该函数…… :param num:参数的描述 :return:返回数值的描述 ''' daima1 daima2 ...... def myabs (num: int ) -> int :print (my_abs(参数))
2、函数的参数 (1)必要传参,位置参数 定义函数时,必须要传递的参数,根据定义的位置进行传送
1 2 3 4 5 def test1 (x,y ): return x + y result = test1(10 ,20 )
(2)关键字传参 1 2 3 4 def test1 (x,y ): return x + y result = test1(y = 10 ,x = 20 )
(3)默认传参 为参数提供默认值,调用函数时不可传该默认参数的值,
1 2 3 4 5 6 7 8 def test2 (x,y,init_sum = 10 ): init_sum += x + y return init_sum print (test(10 ,20 ))print (test(10 ,20 ,100 ))
(4)可变参数,不定长参数 1 2 3 4 5 6 7 8 9 10 11 12 def test3 (*args,init_sum = 10 ): print (type (args)) if args: ''' return init_sum +sum(args)#累加args ''' for i in args: init_sum += i return init_sum print (test3(1 ,2 ,init_sum = 100 ))
1 2 3 4 5 6 7 8 9 10 def test4 (init_num = 10 ,**kwargs ): print (type (**args)) for k,v in kwargs.items(): print (f'参数的名字{k} ,参数的值:{v} ' ) return init_sum + sum (kwargs.values()) test4(x = 10 ,y = 20 ,z = 30 )
传参顺序:位置参数 —>默认传参 —> 不定长普通参数 —> 不定长关键字参数
3、函数的返回值 return 返回函数的值并退出函数
return a,b默认元组
return 后面可连接列表、元组、字典
1 2 3 4 5 6 7 8 9 10 def test1 (): print ('hello,run test1' ) result = test1() def test2 (x,y ): x2 = x ** 2 y2 = y ** 2 return x2,y2 result = test2(3 ,4 ) print (result)print (r1,r2)
4、递归函数与高阶函数 在函数内部调用自己,有退出函数的出口
1 2 3 4 5 6 7 def test (n: int ) ->int : ''' 计算函数阶乘 ''' if n == 1 : return 1 return n * test(n-1 )
匿名函数lambda
如果一个函数有一个返回值,且只有一句代码可使用lambda简化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 lambda 参数列表 : lambda x,y : x + yexa = lambda x,y : x + y print (exa(10 ,20 ))lst = [ {'name' :'zhangs' ,'age' : 34 }, {'name' :'lis' ,'age' :25 }, {'name' :'wangw' ,'age' :22 } ] lst.sort(key = lambda item: item['age' ]) lst.sort(key = lambda item: item['age' ],reverse = True ) print (lst)
高阶函数
把函数作为参数传入,或者返回值是另外一个函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def sum_mun (a,b ): return abs (a) + abs (b) def sum_num2 (a,b,f ): ''' param a: param b: param f:对两个数字进行整理的函数 return: ''' return f(a) + f(b) print (sum_num2(2 ,6 ,abs ))print (sum_num2(2 ,-6 ,lambda n: n ** 2 ))def test3 (*args ): def sum_num (): sum = 0 for n in args: sum += n return sum return sum_nums print (test3(2 ,4 ,6 ,8 )())
内置高阶函数 map函数 接受两个参数,一个是函数名另一个是序列,其功能是将序列中的数值作为函数一次传入到函数值中执行,再返回到列表中,返回值是一个迭代器对象
1 2 3 4 5 list1 = [1 ,2 ,3 ,4 ] map (lambda n: n**2 , [1 ,2 ,3 ,4 ,5 ,6 ])print (list (map (lambda n: n**2 , [1 ,2 ,3 ,4 ,5 ,6 ])))
reduce函数 以一个参数为函数,其返回值为一个值而不是迭代器对象,常用于叠加叠成等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from functools import * reduce(lambda x,y: x + y,[2 ,4 ,6 ,8 ,10 ],10 ) print (reduce(lambda x,y: x + y,[2 ,4 ,6 ,8 ,10 ]))str1 = 'hello world python hello python java hello python flask' lst = str1.split(' ' ) n_lst = list (map (lambda item:{item:1 },lst)) def func (dict1,dict2 ): key = list (dict2.items())[0 ][0 ] value = list (dict2.items())[0 ][1 ] dict1[key] = dict1.get(key,0 ) + value return dict1 print (reduce(func ,n_lst))
filter函数 用于过滤序列和map()类似,接受一个函数和一个序列
1 2 3 4 5 lst1 = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 ] filter (lambda n: n % 2 == 0 ,lst1)
sorted函数 对迭代器进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 lst = [ {'name' :'zhangs' ,'age' : 34 }, {'name' :'lis' ,'age' :25 }, {'name' :'wangw' ,'age' :22 } ] sorted (lst,key = lambda item: item['age' ])sorted (lst,key = lambda item: item['age' ],reverse = True )str_lst ['hello' , 'java' , 'Zoo' , 'world' ] print (sorted (str_lst))print (sorted (str_lst,key = str .upper))
全局变量与局部变量 局部变量:作用范围在函数内部,只能在函数中使用
全局变量:变量之后任何一个地方都可使用
全局变量与局部变量名相同时
1 2 3 4 5 6 7 8 9 def t1 (): b = 100 return b ** (1 /2 ) a = 200 def t2 (): global a a = 30 print (a) print (a)
文件和目录的操作 文件流:源或者目标都是文件的流
1、文件流的操作
(1)读 1 2 3 4 5 6 7 8 open ('file position' ,mode,encoding = '编码格式' )f = open ('file position' ,'r' ,'gbk' ).read() f.readline() f.readlines()
(2)写 1 2 3 4 5 6 wf = open ('position' ,'w' ,'gbk' ) for i in range (3 ): wf.write('hello\n' ) wf.close()
(3)指针 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 wf = open ('position' ,'w' ,'gbk' ) for i in range (3 ): print (f'now_position:{wf.tell()} ) wf.write(' hello\n') wf.close() #0 7 14 wf = open(' position',' r+',' gbk') #指针移到第一个hello后面 #wf.seek(偏移量,起始位置) wf.seek(5,0) #读取第一个hello后面的内容 after = wf.read() wf.seek(5,0) wf.write(' world'+after) wf.close()
(4)with语句 1 2 3 4 with open ('file' , 'w' ,encoding = 'gbk' ) as f: for i in range (10 ): f.write('hello\n' ) f.close()
文件和文件夹的操作 借助os模块
面向对象编程 类:是对一些列具有 相同特征和行为 的事物的统称
对象:是基于类创建出来的真实存在的事物
1 2 3 4 5 6 7 8 class 类名 (): 属性1 属性2 函数1 函数2 ……
创建对象 访问对象的属性和函数 1、类外面访问
对象名.属性名字
对象名.函数名字
2、类里面访问
self.属性名字
self.函数名字
魔术函数 在python中,_ _ xx_ _()的函数叫做魔法函数,是指具有特殊功能或者特殊含义的函数,在某种情况下子调用的
init函数
str 函数
当print输出对象的时候默认打印对象的内存地址。如果定义了_ _ str _ _ 方法,那么就会打印从这个函数中return的数据
1 2 3 4 def __str__ (self ): return
del 函数
删除对象是,python解释器也会默认使用_ _ del _ _()函数
例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Car (): def __init__ (self,brand,type_name,category ): print ('starts initializing the car object' ) self .brand = brand self .type_name = type_name self .category = category def run (self ): print (f'{self.brand} -{self.type_name} -{self.category} ' ) print ('开起来' ) def __new__ (cls, *args, **kwargs ): print ('start creating the Car object' ) return super ().__new__(cls) def __str__ (self ): return f' car`s brand is {self.brand} ' def __del__ (self ): print ('start delete object' ) print (c1.brand)c1 = Car('BYD' ,'汉' ,'中型轿车' ) c2 = Car('YQ' , 'maiteng' ,'中型轿车' ) c1.run() c2.run() print (c1)del c1
类属性和实例属性
1、类属性 记录的某项数据始终保持一致时则定义类属性
实例属性 要求 每个对象为其 单独开辟一份内存空间 来记录数据,而__类属性__ 为全类所以共有,仅占用一份内存,更加节省内存空间
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Person (): species = 'human' def __init__ (self,name ): self .name = name def setName (self,name ): self .name = "Wang wu" p1 = Person('Zhang San' ) p2 = Person('Li Si' ) p1.name = 'Wang Wu' Person.species = '人科' p1.species = '人属' print (p1.species)print (Person.species)print (p1.name)
类函数和静态函数 1、类函数
1 2 3 4 5 6 7 8 class Person (self ): type_name = 'human' @classmethod def get_tooth (cls ): return cls.type_name
2、静态函数
需要通过安装装饰器@staticmethod 来进行修饰,静态方法既不需要传递类对象也不需要传递实例对象,(形参没有self/cls)。静态方法也能够通过实例对象和类对象去访问
特点
example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Person (): def __init__ (self,name ): self .name = name def eat (self ): print (f'{self.name} 正在吃饭' ) @classmethod def work (cls,other,num = 100 ): print (other) print ('everyone need to do work' ) @staticmethod def run (): print ('everyone can run' ) p1 = Person('Zhang San' ) p1.eat() p1.work('abc' ) Person.work('efg' ) p1.run() Person.run()
继承和重写 1、继承 python面向对象的继承指的是多个类之间的所属关系,即子类默认继承父类的所有属性和函数。
py中所有类默认继承object类,object类时顶级类或基类
(1) 单继承
只继承一个父类
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Animal : name = 'animal' def say (self ): print ('动物的叫声' ) class Dog (Animal ): def see_home (self ): print ('狗可以看家' ) d = Dog() d.say() print (d.name)d.see_home() print (type (d))print (isinstance (d,Dog))print (isinstance (d,Animal))print (issubclass (Dog,object ))
(2)多继承
一个子类继承两个或多个父类,就近原则:第一个继承找不到才会去第二个继承
MRO顺序:采用一个算法将复杂结构上所有的类全部映射到一个先行顺序上,而根据这个顺序就能够保证所有的类都会被构造一次
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Parent (object ): def __init__ (self,name,*args,**kwargs ): self .name = name print ('the init function of the parent is executed' ) def test (self ): print ('the test function of the parent is executed' ) class Son1 (Parent ): def __init__ (self,name,age,*args,**kwargs ): self .age = age super ().__init__(name,*args,**kwargs) print ('the init function of Son1 is executed' ) def test (self ): print ('the test function of the Son1 is executed' ) class Son2 (Parent ): def __init__ (self,name,sex,*args,**kwargs ): self .sex = sex super ().__init__(name,*args,**kwargs) print ('the init function of Son2 is executed' ) def test (self ): print ('the test function of the Son2 is executed' ) class Grandson (Son1,Son2): def __init__ (self,name,age,sex,*args,**kwargs ): super ().__init__(name,age,sex) print ('the init function of Grandson is executed' ) print (f'MRO序列是:{Grandson.__mro__} ' )gs = Grandson('ZS' ,34 ,'male' )
2、重写 父类的函数会被子类继承,当父类中的某个函数不完全适用于子类时,就需要在子类中重写父类的这个函数,且函数名字必须一模一样
super()函数,正在重写父类函数时,让super().调用父类中封装的函数
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Parent : def __init__ (self,name ): self .name = name print ('the init function of the parent is executed ' ) def say_hello (self ): print (f'{self.name} :hello' ) print ('the say_hello function of the parent is executed' ) class Son (Parent ): def __init__ (self,name,age ): super ().__init__(name) self .age = age print ('the init function of the son is executed' ) def say_hello (self ): print (f'{self.name} :hello world!' ) print ('the say_hello function of the son is executed' ) s1 = Son('Zhang san' ,32 ) s1.say_hello()
扩展步骤:
1、在子类中重写父类函数
2、在需要的位置使用super().父类函数来调用父类函数的执行
3、代码其他位置只针对子类的需求,编写子类特有的代码实现
私有属性和函数 可以为属性和函数设置私有权限,即设置某个属性或函数不继承给子类。甚至外部调用和访问
设置私有权限的方法:在属性名和函数名前面加上两个下划线__
如果也想要别人去访问和修改私有属性,在python中,一般定义函数名get_xx用来获取私有属性,定义set_xx用来修改私有属性值
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Animal (object ): __name = 'animal' def __init__ (self,color ): self .__color = color def __run (self ): print (self .__name) print ('animal run' ) def say (self ): print ('animals cried out' ) Animal.__name = 'species' print (self .__color) self .__run() def set_color (self,new_color ): self .__color = new_color def get_color (self ): return self .__color class Dog (Animal ): pass d = Dog('red' ) d.set_color('green' ) print (d.get_color())d.say()
面向对象三大特征
将属性和方法书写到类的里面的操作
封装可以为属性和方法添加私有权限
子类默认继承父类的所有属性和方法
子类可以重写父类的属性和方法
传入不哦她那个的对现象,产生不同的结果
模块和包 1、导入模块
import module_name
from module_name import *
from module_name improt function_name
import module_name as alias
from module_name import function_name as alias
example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import random import mathprint (math.log(9 ,3 ))print (math.log2(8 ))from math import *print (log2(8 ))print (log(9 ,3 ))from math import log2,log10print (log10(1000 ))import multiprocessing as mpfrom math import log2 as lg2print (lg2(16 ))
自定义模块 自定义模块必须符合标识符命名规则
定义模块
测试模块
导入模块
注意事项
4.1导入多个模块时,且模块内有同名功能,调用这个同名功能时,调用到的是后面导入模块的功能
4.2当导入一个模块,python解释器对模块搜索的顺序是:当前目录—>在shell变量pythonpath下的每一个目录。sys.path可以查看
4.3文件名不要和已有模块重复
example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def my_sum (n ): ''' calculate the sum from 0 to n :param n:positive integer :return: ''' s = 0 for i in range (n+1 ): s += i return s def test (n:int ) -> int : ''' calculate the factorial from 0 to n :param n: positive integer :return: ''' if n == 1 : return 1 return n * (test(n-1 )) if __name__ == '__main__' : print (my_sum(10 )) print (test(6 ))
import
1 2 import costom_module1 print (costom_module1.my_sum(10 ))
_ _ all _ _
当使用from xxx import *导入时只能导入
1 2 3 4 5 6 7 __all__ = ['testA' ] def testA (): print ('testA' ) def testB (): print ('testB' )
python的包 模块文件构成,将众多具有香瓜节能功能的模块文件结构化组合形成包
注意 :新建包后,包内不会自动创建_ _ init _ _.py文件,这个包控制着报的导入行为。在 _ _ init _ _.py文件中添加 _ _ all _ _ = [module1,module2],控制允许导入的模块列表(只有在xxx import * 导入时才有效)
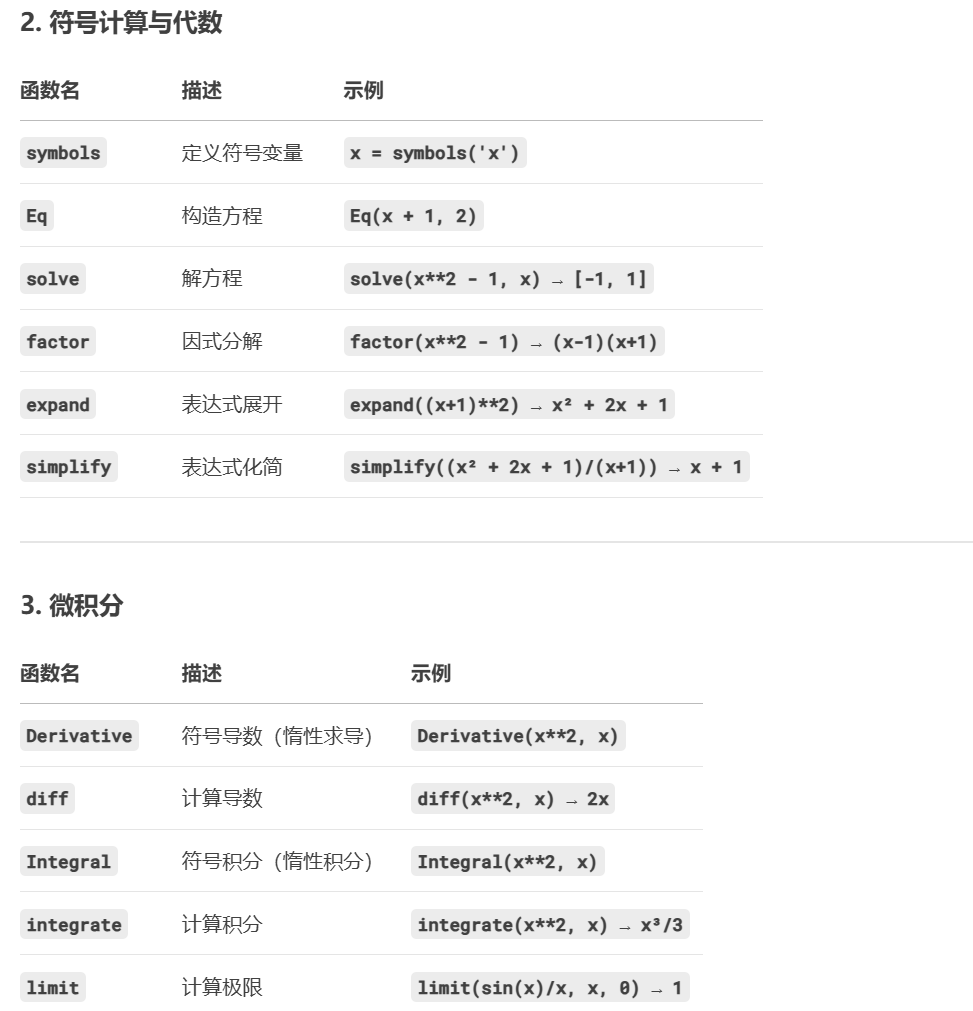
构造方程组 1 2 3 4 5 6 7 8 9 10 from sympy import symbols, Eq, solve x, y = symbols('x y') eq1 = Eq(2*x + 3*y, 8) eq2 = Eq(x - y, 1) sol = solve((eq1, eq2), (x, y)) print(sol)
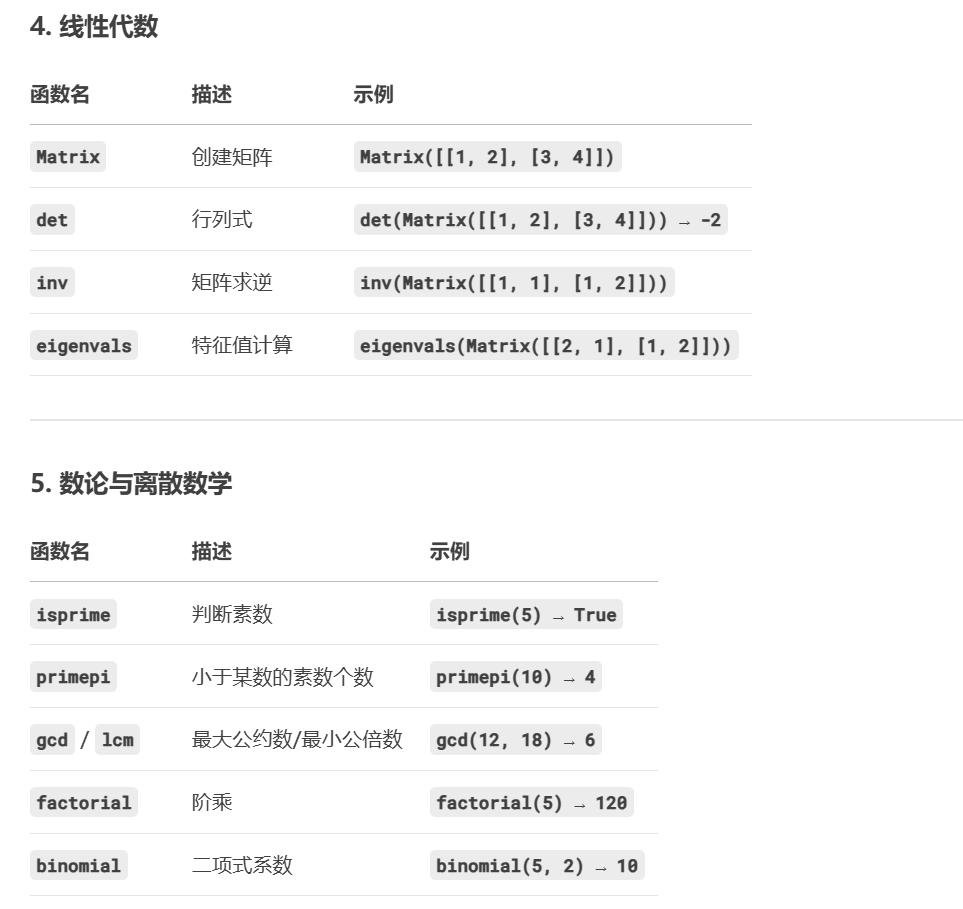
二、库的使用 gmpy2 iroot函数 :
返回两个值
1、开方结果(向下取整)
2、是否完全开放(bool)
gcdext函数:
变量
满足的等式
作用
dd = gcd(e1, e2)e1 和 e2 的最大公约数。
xe1 * x + e2 * y = d用于计算 c1^x(在 RSA 共模攻击中还原 m)。
ye1 * x + e2 * y = d用于计算 c2^y(在 RSA 共模攻击中还原 m)。
如果 d = 1 :x 是 e1 模 e2 的逆元,可直接解密。
如果 d > 1:需对 m^d 开 d 次方才能还原 m。
求整数 a,b的最大公因数
判断一个数是否为素数
判断一个数是否为偶 /奇数
1 2 x = gmpy2.is_even(s) x = gmpy2.is_odd(s)
求一个数模 x的逆元y
求一个整数的 x次幂和摸y取余
扩展欧几里得算法
1 2 s = gmpy2,gcdext(e1 , e2) d , x , y = gmpy2.gcdext(e1 , e2)
sympy 常见函数
解方程组 BUUCTF GWCTF2019 babyrsa
1 2 3 4 5 6 7 from sympy import *f1 = symbols('f1' ) f2 = symbols('f2' ) x = f1+ f2-c1 y = f1**3 + f2**3 -c2 intr = solve([x,y],[f1,f2]) print (intr)
函数/类
所属库
主要用途
输入示例
输出示例
sympy.DerivativeSymPy
符号微分(求导)
Derivative(x**2, x)2*x
fractions.Fraction标准库
精确表示分数
Fraction(1, 3)1/3
2、from…… 1)from Crypto.PublicKey import RSA(公钥解析) 1 2 3 f1 = open ("G:\\crpyto learning\\攻防世界\\best_rsa\\publickey1.pem" ,"rb" ).read() pub1 = RSA.importKey(f1) n1 = pub1.n