
misc??
部分文件头:
PNG:
文件头是89 50 4E 47
文件尾是AE 42 60 82
JPEG:
文件头是FF D8 FF,文件尾是FF D9
TGA:
未压缩的前4字节是00 00 02 00,RLE压缩的前5字节是00 00 10 00 00
GIF:
文件头是47 49 46 38 39(37) 61,文件尾是00 3B
BMP:
文件头是42 4D
TIFF:
文件头是49 49 2A 00
zip伪加密
压缩源文件数据区:
50 4B 03 04:这是头文件标记(0x04034b50)
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密) 头文件标记后2bytes
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
00 00:扩展记录长度
6B65792E7478740BCECC750E71ABCE48CDC9C95728CECC2DC849AD284DAD0500
压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记(0x02014b50)
3F 00:压缩使用的 pkware 版本
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密,伪加密的关键) 目录文件标记后4bytes
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
24 00:扩展字段长度
00 00:文件注释长度
00 00:磁盘开始号
00 00:内部文件属性
20 00 00 00:外部文件属性
00 00 00 00:局部头部偏移量
压缩源文件目录结束标志:
50 4B 05 06:目录结束标记
00 00:当前磁盘编号
00 00:目录区开始磁盘编号
01 00:本磁盘上纪录总数
01 00:目录区中纪录总数
59 00 00 00:目录区尺寸大小
3E 00 00 00:目录区对第一张磁盘的偏移量
00 00:ZIP 文件注释长度
wireshark检索词
1 |
例题
[1]BUUCTF ACTF RSA0
用010editor打开zip文件,全局防伪标记为00 00,将文件中的所有09 00改成00 00
打开py文件,输出对应output文件中的内容,进行常规rsa解密
[2]BUUCTF zip伪加密
一、无加密
压缩源文件数据区的全局方式位标记应当为00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为00 00 (50 4B 01 02 14 00 后)
二、伪加密
压缩源文件数据区的全局方式位标记应当为 00 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为 09 00 (50 4B 01 02 14 00 后)
三、真加密
压缩源文件数据区的全局方式位标记应当为09 00 (50 4B 03 04 14 00 后)
且压缩源文件目录区的全局方式位标记应当为09 00 (50 4B 01 02 14 00 后)
第二个数字为奇数时有加密,偶数无加密
LSB
[1]BUUCTF LSB
根据题目提示可以用sagesolve
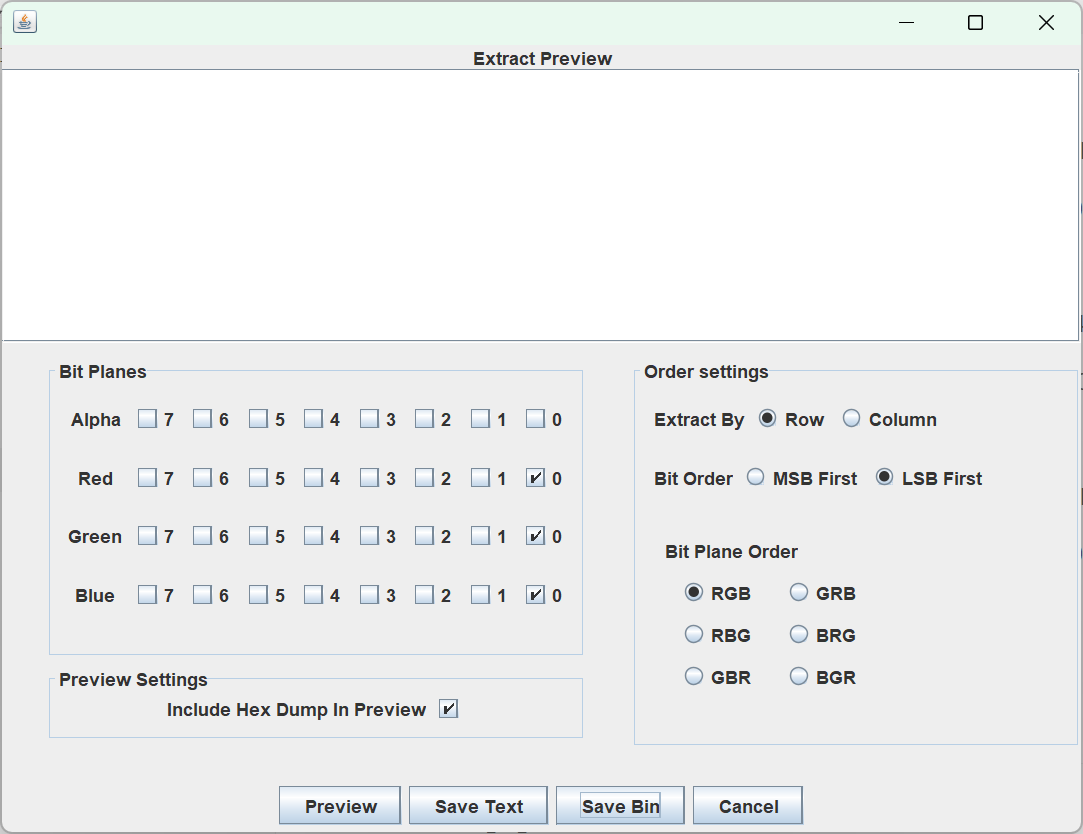
点击savebin 保存为filename.png 获得二维码即为flag
??未知
binwalk扫描出zip
foremost生成output文件爆破zip得flag
serpent 解码:http://serpent.online-domain-tools.com/
例题BUUCTFsnake
exp:压缩包解密出来获得提示:What is Nicki Minaj
What is Nicki Minaj’s favorite song that refers to snakes?
纸箱nicki minaj这个歌手 和snake有关的歌名为anaconda 将其作为key 放入网站解码获得flag
base64伪加密
解密脚本(大佬的)
1 | def base64value(c): |
文件隐写
BUUCTF outguess
在kali中使用exiftool打开mmm.jpg会发现社会主义核心价值观加密,解密后得到abc,猜测为outguess的key
在kali中打开outguess
1 | outguess -k 'abc' -r mmm.jpg flag.txt |
后再次打开flag.txt获得flag
NSSCTFhuaji?
kali binwalk扫描发现压缩包,内flag.txt无内容,继续从图片中找线索 在exiftool查看发现一串数字用16进制转ASCII结果为压缩包密码
输入后获得flag
[2]excel破解
获得的excel表格带有密码 直接用记事本打开查找flag
exe??base64转图片
n种解决方法
010editor打开KEY.exe发现base64编码,截取第一段进行解密发现PNG的字样
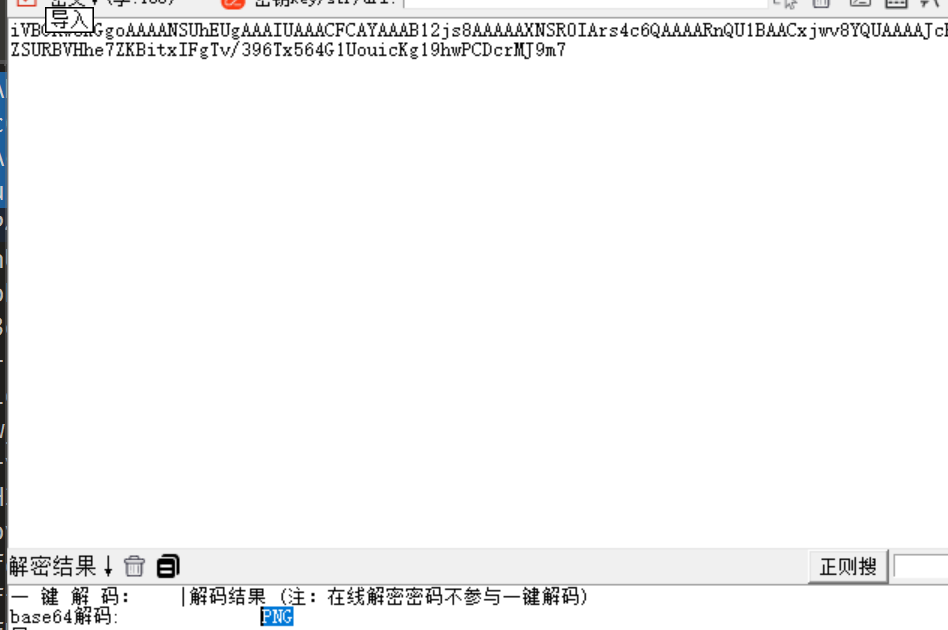
将完整编码复制到随波逐流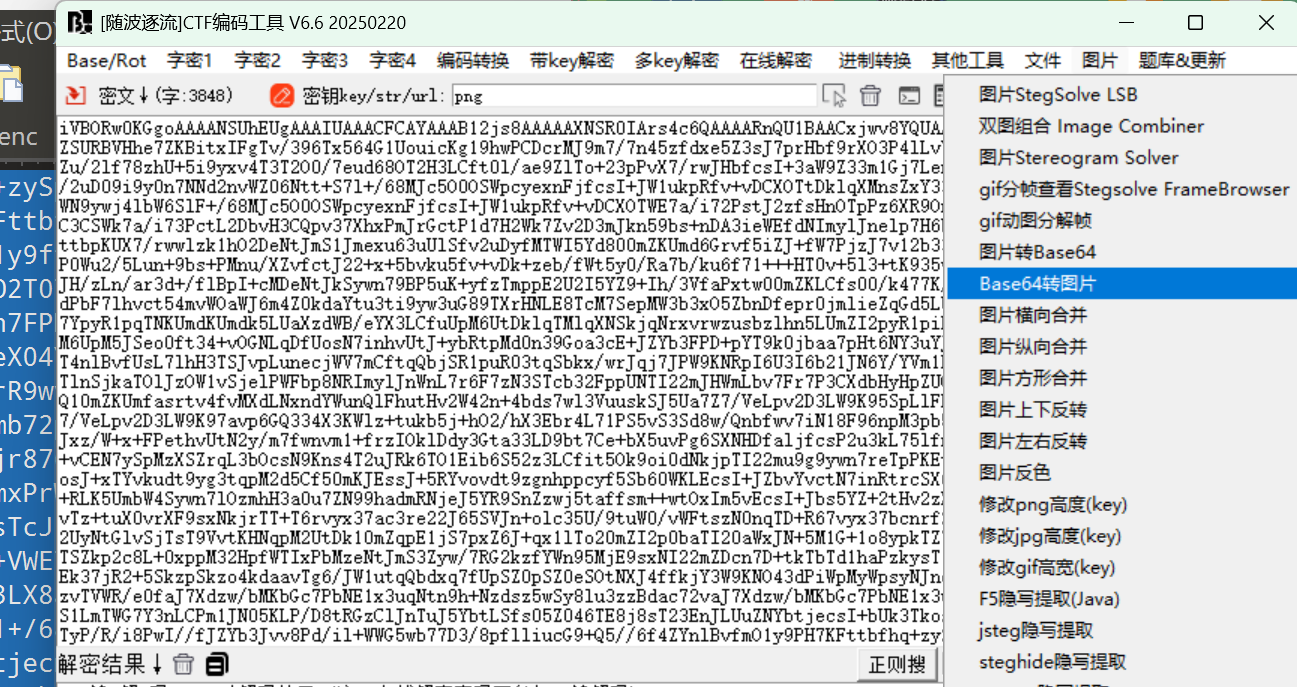
密钥处输入png,base64转图片,扫描二维码
整合文件
1 | copy /b filepath + filepath > filepath |
ISCC 书法大师
图片foremost提取出zip
扫描图片查看exif信息
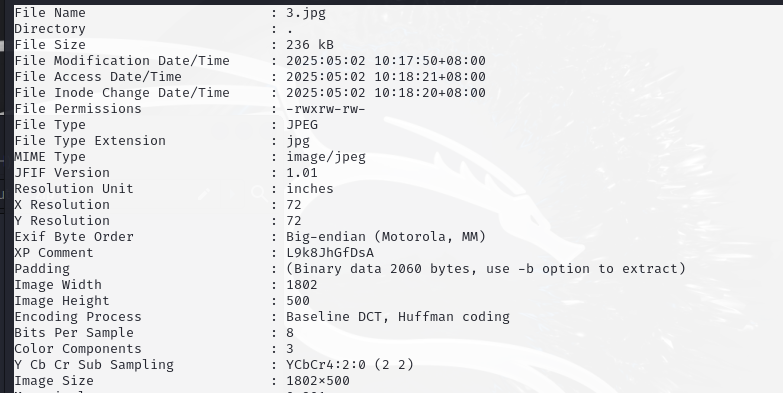
xp comment是压缩包解压密码
解压之后文本文档将文字转为笔画数

笔画转为16进制



ZIP明文攻击
这个问题问得非常好!它涉及了 bkcrack 使用的ZIP传统加密算法漏洞原理,以及为何**只凭 flag.zip 的尾部(已知明文)**就能破解出整个 flag.zip 的加密密钥,进而解密 attachment.zip 中的加密内容。
下面我分步骤解释这个原理。
🔐 一、ZIP 的传统加密机制存在严重弱点
ZIP 文件有两种加密方式,其中一种是所谓的“传统 PKZIP 加密”(也叫 ZIP legacy encryption),其核心特点是:
- 使用一个 96 位(3 个 32-bit)内部密钥 (key X, Y, Z)
- 加密过程是流加密(stream cipher),每个字节的加密只与密钥有关
⚠️ 问题是:这个加密方式的密钥初始化和加密逻辑存在严重漏洞。在 1994 年,Biham 和 Kocher 发表了一种已知明文攻击(Known Plaintext Attack),可以在已知少量明文的情况下推导出全部密钥。
🔍 二、已知明文攻击的核心思路
已知明文攻击(KPA)原理:
- 如果你知道加密文件中某一段明文的确切位置和内容,你就能:
- 从密文和明文对比推出部分密钥状态
- 根据 ZIP 加密算法的规律反推出完整密钥
- 用这个密钥解密整个 ZIP 文件
🧩 三、为什么用 ZIP 文件尾部就够?
ZIP 文件末尾有个固定的结构,叫 End of Central Directory Record (EOCD),长度是 22 字节,内容是固定格式(大多数压缩软件写出来都一样)。
所以:
- 你知道
flag.zip是一个 ZIP 文件; - 那么你就能非常自信地猜出它的最后 22 字节是什么;
- 这 22 字节就是你已知的明文;
- 再告诉
bkcrack:密文从哪开始对应这段明文(用-x指定偏移); bkcrack利用这个明文片段恢复出 ZIP 解密的三个内部密钥(X, Y, Z);- 一旦恢复了密钥,就可以直接解密加密的
flag.zip文件,甚至还可以换密码!
💡 所以:哪怕你不知道密码,只要你知道加密内容中一小段明文,就能反推出密钥!
🔁 四、为什么能解密 attachment.zip 中的 flag.zip
这是因为:
attachment.zip中的flag.zip是使用传统加密方式加密的;bkcrack并不关心加密内容在attachment.zip里还是单独文件;- 它只要:
- 加密后的
flag.zip(即-c参数指向密文); - 还有一小段你知道确切内容的部分(已知明文);
- 加密后的
- 就能恢复出密钥并解密整份
flag.zip。
📦 bkcrack 用法(中文翻译)
利用 Biham 和 Kocher 的已知明文攻击破解传统 ZIP 加密(ZipCrypto)。
一、获取内部密码表示(即恢复加密密钥)
| 参数 | 含义 |
|---|---|
-c, --cipher-file <文件> |
包含密文的 ZIP 条目或磁盘上的文件 |
--cipher-index <索引> |
ZIP 中密文条目的索引号 |
-C, --cipher-zip <压缩包> |
包含密文条目的 ZIP 压缩包 |
| 参数 | 含义 |
|---|---|
-p, --plain-file <文件> |
包含明文的 ZIP 条目或磁盘上的文件 |
--plain-index <索引> |
ZIP 中明文条目的索引号 |
-P, --plain-zip <压缩包> |
包含明文条目的 ZIP 压缩包 |
| 其他相关参数 | 含义 |
|---|---|
-t, --truncate <大小> |
最多加载多少字节的明文 |
-o, --offset <偏移> |
明文相对于密文的偏移量(不含加密头,可为负) |
-x, --extra <偏移> <十六进制数据> |
在指定偏移处增加额外明文(十六进制),可为负 |
--ignore-check-byte |
不使用密文字节的校验位作为已知明文 |
| 高级选项 | 含义 |
|---|---|
--continue-attack <检查点> |
从上次攻击的中断点继续,适用于非穷举或中断的攻击 |
--password <密码> |
从密码派生出内部密码值(高级用途,如反转 --change-password 的效果) |
二、使用已知密钥执行操作
| 参数 | 含义 |
|---|---|
-k, --keys <X> <Y> <Z> |
使用 3 个十六进制整数形式的内部密码(需要搭配 -d、-U、--change-keys 或 --bruteforce) |
| 解密相关 |
|---|
-d, --decipher <文件> |
--keep-header |
| 修改加密压缩包 |
|---|
-U, --change-password <压缩包> <新密码> |
--change-keys <压缩包> <X> <Y> <Z> |
三、暴力破解密码
| 参数 | 含义 |
|---|---|
-b, --bruteforce <字符集> |
使用指定字符集生成并测试密码候选项以尝试破解密码(或等效密码) |
支持的字符集快捷方式:
| 快捷方式 | 描述 |
|---|---|
?l |
小写字母:abcdefghijklmnopqrstuvwxyz |
?u |
大写字母:ABCDEFGHIJKLMNOPQRSTUVWXYZ |
?d |
数字:0123456789 |
?s |
特殊字符:!"#$%&'()*+,-./:;<=>?@[\]^_{ |
?a |
字母数字:等同于 ?l?u?d |
?p |
所有可打印 ASCII:等同于 ?l?u?d?s |
?b |
所有字节(0x00 - 0xFF) |
| 参数 | 描述 |
|---|---|
-l, --length [<最小>..<最大>] |
指定密码长度范围或具体长度(配合 --bruteforce) |
-r, --recover-password [<长度>] <字符集> |
快捷方式,同时指定密码长度和字符集,相当于 --length 与 --bruteforce |
| 其他 |
|---|
--continue-recovery <检查点> |
四、其他选项
| 参数 | 描述 |
|---|---|
-j, --jobs <线程数> |
设置并行线程数 |
-e, --exhaustive |
完全穷举所有解(密钥或密码),而不是找到一个就停止 |
-L, --list <压缩包> |
列出压缩包内文件并退出 |
--version |
显示版本信息后退出 |
-h, --help |
显示帮助信息后退出 |
图片隐写
图片高度修改
NSSCTF GFCTF pikapika!
jpg文件放入010editor中发现有隐藏png图片,binwalk提取有zip
跟据jpg图片上的字母拼出zip解压密码I_want_a_p1ka!
得到wav音频文件 发现只有两种频率,提取为二进制文件并转化为字符
1 | import wave |
发现文本文件为base64,base64解码
1 | import base64 |
得到的文件放入010editor,文件头为png
修改文件后缀得到图片发现 图片高度被修改放入随波逐流自动修复图片高度获得flag





